
티스토리 뷰
효율적으로 Pod를 Node에 스케쥴링 하기위해 Resource를 최적화 하는것이 좋다. 잘못된 Sizing으로인해 많은 자원을 유휴 자원으로 낭비하거나 성능을 떨어뜨려 최악의 상황엔 Pod가 죽는 상황까지 유발한다.

일반적으로 Pod의 Resource를 지정해야할 경우 아래와 같이 Request와 Limit값을 설정할 수 있다.
resources:
limits:
memory: 2Gi
cpu: 1000m
requests:
memory: 1Gi
cpu: 500mThe lifecycle of a Kubernetes Pod
As you know, limits can be higher than the requests. What if you have a Node where the sum of all the container Limits is actually higher than the resources available on the machine?
At this point, Kubernetes goes into something called an “overcommitted state.” Here is where things get interesting. Because CPU can be compressed, Kubernetes will make sure your containers get the CPU they requested and will throttle the rest. Memory cannot be compressed, so Kubernetes needs to start making decisions on what containers to terminate if the Node runs out of memory.
리소스 설정 시 limits은 requests보다 높을 수 있다. 모든 컨테이너 limits의 합계가 실제로 시스템에서 사용 가능한 리소스보다 높은 노드가 있는 경우, Kubernetes는 "overcommitted state"로 전환되는데, 여기서 흥미로운점은 CPU는 압축될 수 있기 때문에 Kubernetes는 컨테이너가 요청한 CPU를 확보하고 나머지는 제한하는데 반해 메모리는 압축할 수 없으므로 Kubernetes는 노드의 메모리가 부족할 경우 종료할 컨테이너에 대한 결정을 시작한다.
Kubernetes requests vs limits: Why adding them to your Pods and Namespaces matters | Google Cloud Blog
While your Kubernetes cluster might work fine without setting resource requests and limits, you will start running into stability issues as your teams and projects grow. Adding requests and limits to your Pods and Namespaces only takes a little extra effor
cloud.google.com
Overcommitted State
k8s에 파드를 띄울때 리소스 제한을 설정하지 않으면 Node의 cpu, memory 를 서로 공유 하게된다.
즉 Pod 하나가 Node의 모든 자원을 사용하게 될 수 있다.
일반적인 경우에는 문제가 없으나 Pod가 동시에 많은 cpu, memory 자원을 사용하려고 할때 문제가 발생한다.
CPU
CPU 의 경우 Node의 Core 수를 넘어서는 요청이 들어오면 오버커밋 상황이 되며 기대하는 응답 보다 느리게 동작한다. 이 경우에는 초과되는 요청을 한 파드가 퇴거(evict) 대상으로 지정되지 않으며, 단지 Node성능이 저하된다.
MEMORY
메모리의 경우 이와 다르게 최대 메모리 를 넘어서는 Overcommitted 상황이 되면 OOM 이 발생한 Pod나 퇴거 대상인 파드들 부터 순차적으로 종료 시킨다(OOM Killed). 경우에 따라 Node 자체가 멈추거나 응답이 없는 경우도 발생한다.
OOM Killed
컨테이너의 메모리 사용량이 메모리 제한을 초과하거나, 컨테이너가 실행 중인 노드의 메모리 부족 상태가 발생하면 Out Of Memory(OOM)가 발생한다.
Containers:
simmemleak:
Image: saadali/simmemleak:latest
Limits:
cpu: 100m
memory: 50Mi
State: Running
Started: Tue, 07 Jul 2019 12:54:41 -0700
Last State: Terminated
Reason: OOMKilled
Exit Code: 137
Started: Fri, 07 Jul 2019 12:54:30 -0700
Finished: Fri, 07 Jul 2019 12:54:33 -0700
Ready: False
Restart Count: 5
Conditions:
Type Status
Ready False
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 42s default-scheduler Successfully assigned simmemleak-hra99 to kubernetes-node-tf0f
Normal Pulled 41s kubelet Container image "saadali/simmemleak:latest" already present on machine
Normal Created 41s kubelet Created container simmemleak
Normal Started 40s kubelet Started container simmemleak
Normal Killing 32s kubelet Killing container with id ead3fb35-5cf5-44ed-9ae1-488115be66c6: Need to kill Podhttps://kubernetes.io/ko/docs/concepts/configuration/manage-resources-containers/
파드 및 컨테이너 리소스 관리
파드를 지정할 때, 컨테이너에 필요한 각 리소스의 양을 선택적으로 지정할 수 있다. 지정할 가장 일반적인 리소스는 CPU와 메모리(RAM) 그리고 다른 것들이 있다. 파드에서 컨테이너에 대한 리소
kubernetes.io
Sizing Pods for JVM
Java Application의 Pod를 Sizing하기 위해 기본적으로 JVM의 메모리 구조를 이해하는것이 좋다.
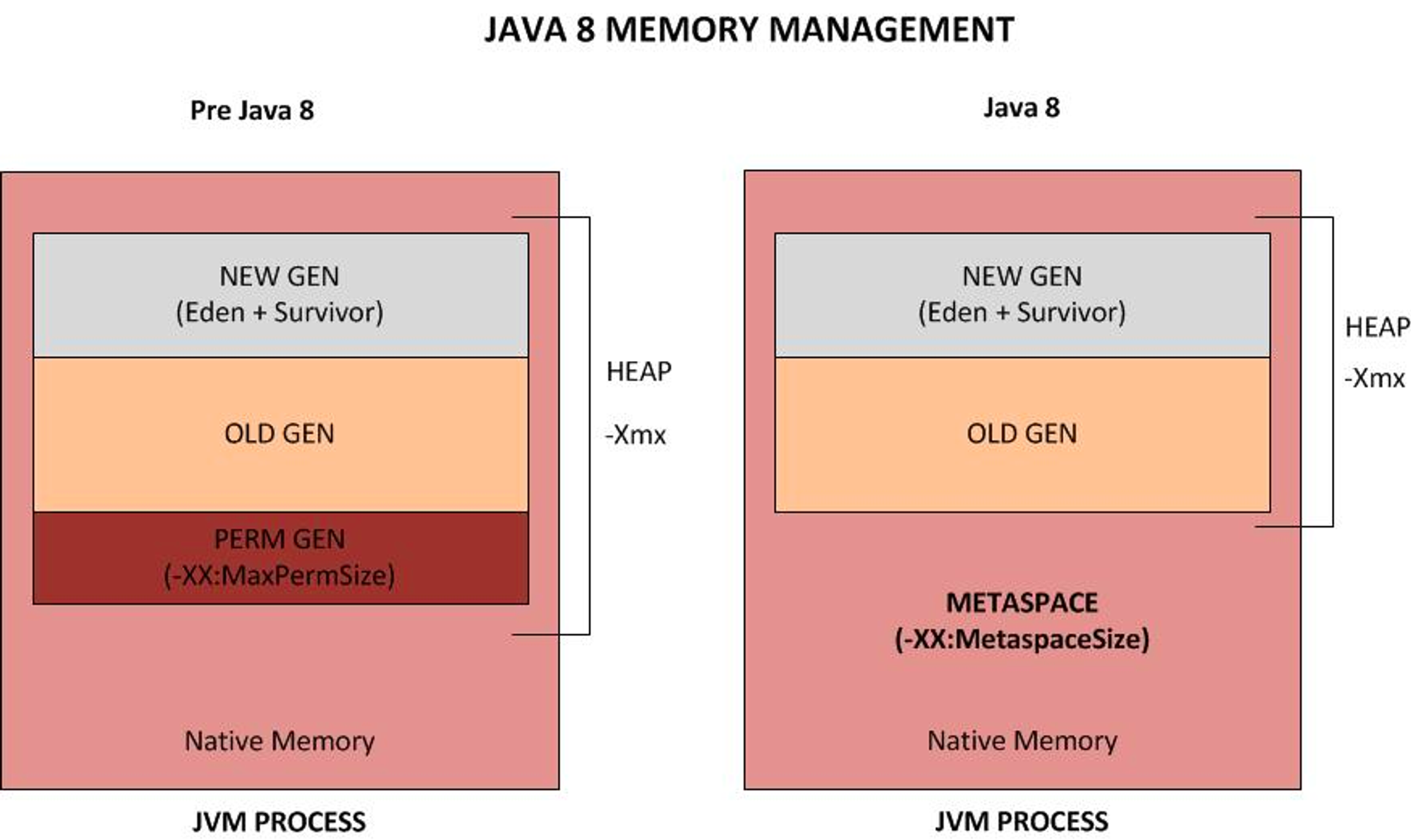
Java 실행 시 Heap사이즈 지정을 안해줄 경우 Pysical Memory를 기반하여 InitialHeapSize (-Xms = Pysical Memory / 4), MaxHeapSize( -Xmx = Pysical Memory / 64)를 할당한다.
Oracle JVM의 경우 (openjdk도 확인 결과 동일) Initial heap size of 1/64 of physical memory up to 1Gbyte
Maximum heap size of 1/4 of physical memory up to 1Gbyte
아래와 같이 64GB의 메모리를 사용하는 머신의 경우, InitialHeapSize는 1GB, MaxHeapSize는 16GB의 메모리가 할당된다.
Pysical Memory Infomation

$ cat /proc/meminfo
MemTotal: 65045780 kB
MemFree: 46301784 kB
MemAvailable: 58742912 kB
Buffers: 134212 kB
Cached: 11050544 kB
Default JVM Memory Infomation

$ java -XX:+PrintFlagsFinal -version 2>&1 | grep -i -E 'heapsize|metaspacesize|version'
size_t ErgoHeapSizeLimit = 0 {product} {default}
size_t HeapSizePerGCThread = 43620760 {product} {default}
size_t InitialBootClassLoaderMetaspaceSize = 4194304 {product} {default}
size_t InitialHeapSize = 996147200 {product} {ergonomic}
size_t LargePageHeapSizeThreshold = 134217728 {product} {default}
size_t MaxHeapSize = 15911092224 {product} {ergonomic}
size_t MaxMetaspaceSize = 18446744073709547520 {product} {default}
size_t MetaspaceSize = 21807104 {pd product} {default}
uintx NonNMethodCodeHeapSize = 5825164 {pd product} {ergonomic}
uintx NonProfiledCodeHeapSize = 122916538 {pd product} {ergonomic}
uintx ProfiledCodeHeapSize = 122916538 {pd product} {ergonomic}
size_t ShenandoahSoftMaxHeapSize = 0 {manageable} {default}
Heap 메모리 지정 시 할당된 Memory
-Xms = 256m, -Xmx512m 할당 후 실행

$ jps -lv
1 app.jar -Xms256m -Xmx512m
총 new gen + tenured gen = 78720K + 174784K = 253504K = 256m

$ jcmd 1 GC.heap_info
1:
def new generation total 78720K, used 44453K [0x00000000e0000000, 0x00000000e5560000, 0x00000000eaaa0000)
eden space 70016K, 61% used [0x00000000e0000000, 0x00000000e2a28ee0, 0x00000000e4460000)
from space 8704K, 14% used [0x00000000e4ce0000, 0x00000000e4e20738, 0x00000000e5560000)
to space 8704K, 0% used [0x00000000e4460000, 0x00000000e4460000, 0x00000000e4ce0000)
tenured generation total 174784K, used 33031K [0x00000000eaaa0000, 0x00000000f5550000, 0x0000000100000000)
the space 174784K, 18% used [0x00000000eaaa0000, 0x00000000ecae1d88, 0x00000000ecae1e00, 0x00000000f5550000)
Metaspace used 90229K, capacity 92928K, committed 93056K, reserved 1130496K
class space used 11055K, capacity 12132K, committed 12160K, reserved 1048576K
Suggestions for Optimization
First, although not related to the OMM kill: just set -Xmx = and ensure your JVM reserves all the heap it will use up-front. Having both JVM and Docker (or cgroups to be precise) growing memory dynamically just makes it harder to reason about capacity or understanding this type of issues.
첫째, OMM killed와 별개로 -Xmx = -Xms를 동일하게 설정하고, JVM이 사용할 모든 힙을 사전에 예약해야 한다. JVM과 Docker(정확하게는 cgroup) 모두 메모리를 동적으로 증가시키면 용량에 대한 추론 및 문제 이해가 더 어려워지기 때문이다.
FROM openjdk:8u181-jre-slim
...
ENTRYPOINT exec java -Xmx1024m -Xms1024m [...] -cp app:app/lib/* com.schibsted.yada.YadaSecond, requests should be at least bigger than -Xmx, and ensure that to add enough head room for the JVM and the OS. How much more? Depends on what runs inside your container. A simple microservice will probably be fine with requests ~%25 higher than -Xmx. But does your microservice (or any library inside it) use off-heap memory? Write logs in a tmpfs volume? Read/Write volumes shared with other containers in the pod? All these (and other factors) impact your memory footprint. You need to know this in with reasonable detail if you want to avoid surprises.
둘째, requests 설정은 -Xmx 설정된 memory값 이상이어야 하며 JVM 및 OS에 사용가능한 여유분(head room)을 추가해야 한다. 단순 마이크로서비스는 -Xmx보다 25% 높게 requests를 설정해도 무방하지만, 마이크로서비스내에(또는 그 안에 있는 라이브러리) Off-heap(heap 외 메모리 저장소)를 사용하거나 tmpfs(temporary file storage) 볼륨을 사용할 경우, 이러한 외부 요소가 리소스 사용에 영향을 미치기 때문에 되도록 피하는게 좋다.
Third, setting limits much higher than requests is meant to handle bursts of activity where your pod makes use of “memory that happens to be available”. Notice the wording. If getting that extra memory is a necessity for your app to do its job, don’t gamble and just reserve it up-front with requests.
셋째, requests 훨씬 높은 limits설정하는 것은 Pod가 사용 가능한 메모리를 사용하는 대량의 작업을 처리하는 것을 허용한다. 서비스가 워크로드를 수행하기 위해 추가 메모리를 필요로 하는경우 도박을 하지 말고 requests 를 미리 예약해야한다.
Fourth, running applications inside containers forces us to have a solid idea of the memory requirements. I left unanswered why our JVM is using ~3.6GiB despite having 1.5GiB max heap, and no off-heap memory, I’ll try to write a followup to go deeper into this. But, assuming we know our memory footprint, my intuition (as a non-Kubernetes expert) is that we should prefer to have requests == limits at least for memory.
넷째, 컨테이너 내 실행중인 응용프로그램의 메모리 요구 사항에 대한 명확한 개념이 필요하다. 최대 힙이 1.5GiB이고 off-heap메모리를 사용하지 않음에도 불구하고 JVM이 ~3.6GiB를 사용하는 이유등이 발생할 수 있기때문이다. 그러나 응용프로그램에서 사용하는 메모리에 대한 공간을 명확히 알고 있다고 가정할 때, requests == limits이 같도록 설정하는것이 좋다.
resources:
limits:
memory: 2Gi
cpu: 1000m
requests:
memory: 2Gi
cpu: 1000mhttps://srvaroa.github.io/jvm/kubernetes/memory/docker/oomkiller/2019/05/29/k8s-and-java.html
'Developer' 카테고리의 다른 글
| How to use KEDA (0) | 2022.10.25 |
|---|---|
| TrafficManagement with ISTIO on EKS (0) | 2022.09.26 |
| Component Tests with Spring Application (0) | 2022.08.11 |
| Kubernetes Liveness & Readiness Probe with Spring boot (0) | 2022.07.26 |
| Configure AWS Credentials For GitHub Actions with OIDC (0) | 2022.06.05 |
- Total
- Today
- Yesterday
- NGINX
- 비교구문
- 조동사
- AWS
- 스페인 여행
- Python Django
- 도덕경
- memcached
- PostgreSQL
- 비지니스 영어
- k8s
- 대명사 구문
- Business English
- redis
- it
- 가정법
- 여행
- mongoDB
- 영문법
- Python
- 다낭
- 베트남
- ubuntu
- hdfs
- 해외여행
- nodejs
- maven
- JBOSS
- hadoop
- 영작
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |